|
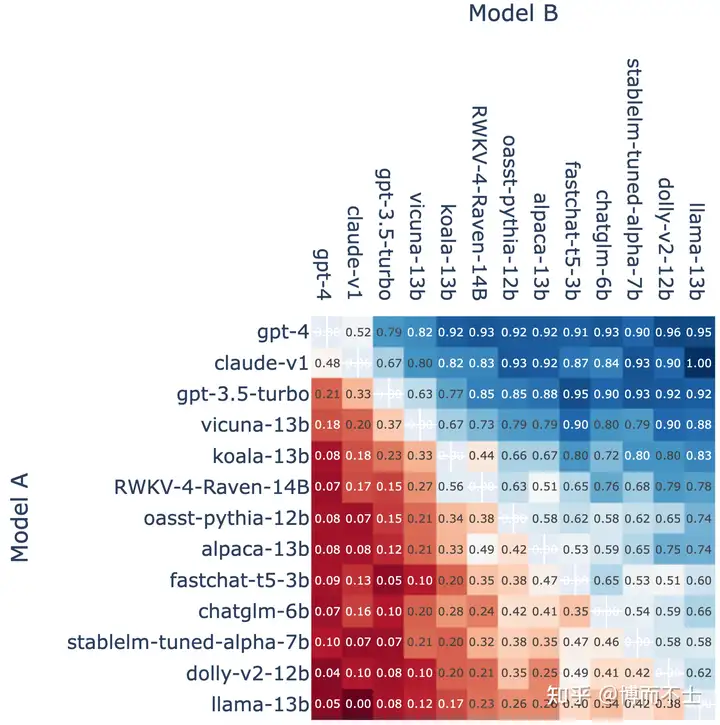
聊天机器人是一种能够与人类进行自然语言交互的智能系统,它们在各个领域都有着广泛的应用和前景。随着大型语言模型(LLM)的出现和发展,聊天机器人的性能和能力也得到了显著的提升。LLM是一种利用大量文本数据来学习语言知识和规律的深度神经网络模型,它们可以生成流畅、连贯、有意义的文本,甚至可以完成一些特定的任务或目标。目前,LLM已经成为了聊天机器人领域的主流技术之一,吸引了众多的研究者和开发者。为了促进LLM在聊天机器人领域的发展和创新,LMSYS Org创建了一个名为Chatbot Arena的平台。LMSYS Org是一个由加州大学伯克利分校的学生和教师组成的开放研究组织,它旨在通过共同开发的方式,使大型模型更加易于使用和可访问。Chatbot Arena是一个LLM基准平台,它展示了不同的聊天机器人模型在与真实用户对话中的性能和评分。该平台每周更新一次排行榜,根据模型与用户对话的结果来计算模型的Elo评分。Elo评分是一种衡量模型相对水平和优劣的指标,它根据模型之间的胜负关系来动态调整。 本文将对第二周Chatbot Arena排行榜上的模型进行分析,第二周排行榜上共有十三个模型参与了竞争,其中有六个模型是新加入的。具体排名情况如图所示。排名前三名的模型分别是GPT-4、Claude-v1和GPT-3.5-turbo,它们都是由知名的公司或机构开发的专有模型,具有较高的技术水平和创新性。GPT-4是OpenAI最新推出的聊天机器人模型,它基于GPT-3进行了改进和扩展,拥有超过1000亿个参数,可以生成高质量、多样化、有逻辑性和一致性的文本。Claude-v1是Anthropic最新推出的聊天机器人模型,它基于Transformer进行了改进和优化,拥有超过500亿个参数,可以生成高质量、多样化、有逻辑性和一致性的文本,并且可以根据用户提供的反馈来自我调整。GPT-3.5-turbo是OpenA推出的聊天机器人模型,它基于GPT-3进行了改进和加速,拥有超过300亿个参数,可以生成高质量、多样化、有逻辑性和一致性的文本,并且可以根据用户提供的主题或情感来调整文本的风格和内容。 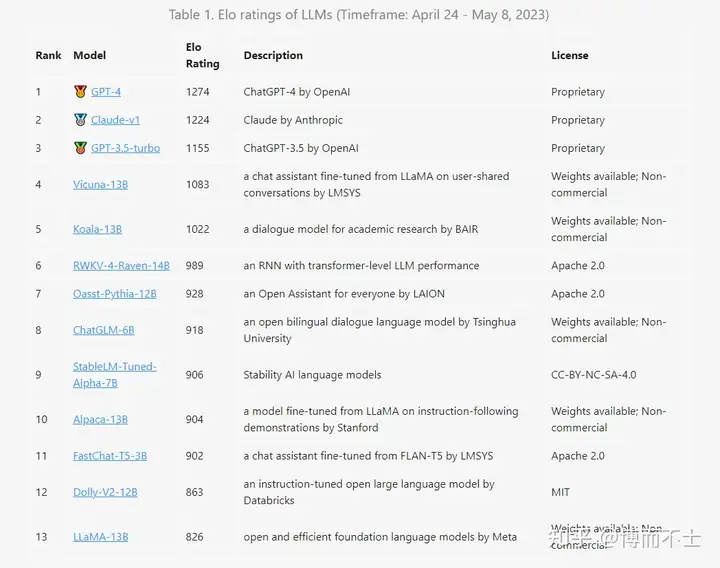 排名第四到第十三名的模型都是由不同的研究机构或组织开发的开放模型,它们具有较高的可用性和多样性。其中,Vicuna-13B、Koala-13B、Alpaca-13B和LLaMA-13B都是基于LLaMA这个开放和高效的基础语言模型进行微调的聊天机器人模型,它们分别在用户共享的对话、学术研究、指令执行等方面进行了专门的训练和优化。RWKV-4-Raven-14B是一个基于循环神经网络(RNN)的聊天机器人模型,它利用了一种新颖的记忆机制,可以达到与Transformer相当的语言建模性能。Oasst-Pythia-12B是一个开放助理模型,它可以根据用户提供的问题或指令来生成合适的回答或行动,并且可以与用户进行多轮对话。ChatGLM-6B是一个开放双语对话模型,它可以同时支持中文和英文,并且可以根据用户提供的语言偏好来自动切换语言。StableLM-Tuned-Alpha-7B是一个基于Stability AI语言模型进行微调的聊天机器人模型,它可以生成稳定、一致、有意义的文本,并且可以避免一些常见的错误或偏差。FastChat-T5-3B是一个基于FLAN-T5进行微调的聊天机器人模型,它利用了一种新颖的注意力机制,可以生成快速、流畅、有意义的文本,并且可以与用户进行多轮对话。Dolly-V2-12B是一个基于Databricks开放大型语言模型进行指令微调的聊天机器人模型,它可以根据用户提供的指令来生成合适的文本或图像,并且可以与用户进行多轮对话。 下图是所有非平局的A vs. B战斗中,Model A获胜的比例。其中有两个亮点值得关注:
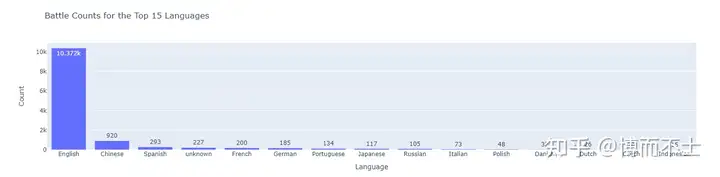
 下图为英文和非英文分来测评的排行榜,通过这个榜单我们就可以看到,为何Claude-v1的测试表现和国内的使用体验差别这么大了: 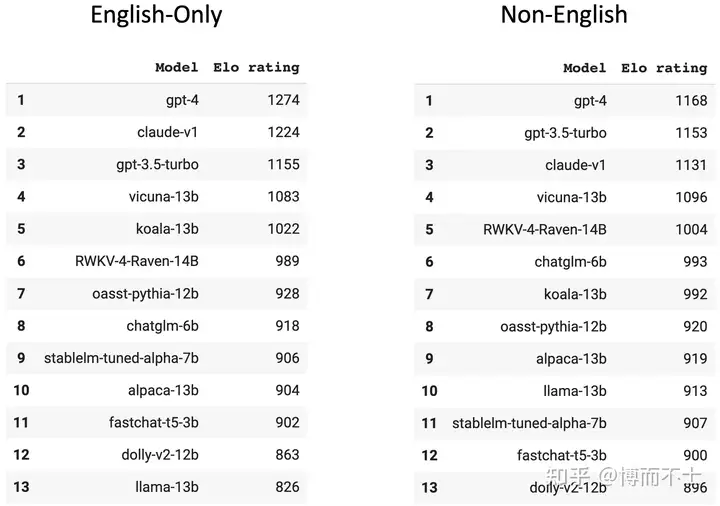
LMSYS Org官网:https://lmsys.org/ 吴恩达提示工程教程:https://mp.weixin.qq.com/s? 原创性承诺:G3(内容由人工列出提纲,AI对提纲进行扩充内容完成文章)kwMjQ5MzExMg==&mid=2247483714&idx=1&sn=5e905f5ec6196f6dc2187db2a8618f02&chksm=c0a5e795f7d26e831292e3e5d468e8287696425d420bb81965a50dcff89986fb435e54dc98d1#rd 特别声明:以上内容(如有图片或视频亦包括在内)来自网络,已备注来源;本平台仅提供信息和存储服务。Notice: The content above (including the pictures and videos if any) is uploaded and posted by user of ASKAI, which is a social media platform focused on technology of CHATGPT and only provides information storage services. |
 |手机版|小黑屋|博士驿站:连接全球智慧,共创博士人才生态圈
( 浙ICP备2023018861号-3 )平台提供新鲜、免费、开放、共享的科技前沿资讯、博士人才招聘信息和科技成果交流空间。
平台特别声明:线上内容(如有图片或视频亦包括在内)来自网络或会员发布,均已备注来源;本站资讯仅提供信息和存储服务。Notice: The content above (including the pictures and videos if any) is uploaded and posted by user , which is a social media platform and only provides information storage services.
|手机版|小黑屋|博士驿站:连接全球智慧,共创博士人才生态圈
( 浙ICP备2023018861号-3 )平台提供新鲜、免费、开放、共享的科技前沿资讯、博士人才招聘信息和科技成果交流空间。
平台特别声明:线上内容(如有图片或视频亦包括在内)来自网络或会员发布,均已备注来源;本站资讯仅提供信息和存储服务。Notice: The content above (including the pictures and videos if any) is uploaded and posted by user , which is a social media platform and only provides information storage services.
GMT+8, 2025-4-19 20:14
Powered by Discuz! X3.5
© 2001-2024 Discuz! Team.





