| Google DeepMind再放AI机器人大招!周五,这家前沿AI研究机构宣布以训练AI聊天机器人的方式训练了一款全新的机器人模型Robotic Transformer 2(RT-2)。
RT-2相当于机器人版ChatGPT,被Google DeepMind称作是其视觉-语言-动作 (VLA)模型的新版本。该模型可以教会机器人更好地识别视觉和语言模态,能够解释人类用自然语言发出的指令,并推断出如何做出相应的行动。它还可以理解英语以外的语言的指示。
结合思维链推理,RT-2可以执行多阶段语义推理。即便是一些抽象概念,RT-2也能理解并指挥机械臂做出正确的动作。比如让它找一把临时用的简易锤子,它会抓起石头;让它给疲惫的人选一款饮料,它会选择红牛;让它把可乐罐移到泰勒·斯威夫特的照片上,它也能顺利完成。 根据论文,RT-2模型基于网络和机器人数据进行训练,利用了谷歌自己的Bard等大型语言模型的研究进展,并将其与机器人数据(例如要移动的关节)相结合,然后将这些知识转化为机器人控制的通用指令,同时保留web-scale能力。 论文地址: https://robotics-transformer2.github.io/assets/rt2.pdf Google DeepMind博客文章写道,RT-2显示出超越其所接触的机器人数据的泛化能力以及语义和视觉理解能力,包括解释新命令并通过执行基本推理(例如关于对象类别或高级描述的推理)来响应用户命令。 其将信息转化为行动的能力表明,机器人有望更快地适应新的情况和环境。 在对RT-2模型进行了超过6000次的机器人试验后,研究团队发现,RT-2在训练数据或“可见”任务上的表现与之前的模型RT-1一样好。它在新奇的、不可预见的场景中的表现几乎翻番,从RT-1的32%提高到62%。 01. 让机器人用AI大模型学习新技能 机器人技术领域正悄然进行一场革命——将大型语言模型的最新进展引入机器人,让机器人变得更聪明,并具备新的理解和解决问题的能力。 《纽约时报》技术专栏作家凯文·罗斯(Kevin Roose)在谷歌机器人部门观看了实际演示,工程师给机器人发出指令:“捡起灭绝的动物”,一个单臂机器人呼呼地响了一会儿,然后伸出机械臂,爪子张开落下,准确抓住了它面前桌子上的恐龙塑料制品。
▲《纽约时报》拍摄的视频 在这场长达1小时的演示中,RT-2还成功执行了“将大众汽车移到德国国旗上”的复杂指令,RT-2找到并抓住一辆大众巴士模型,并将其放在几英尺外的微型德国国旗上。
▲两名谷歌工程师Ryan Julian(左)和Quan Vuong成功指示RT-2“将大众汽车移到德国国旗上”。(图源:《纽约时报》) 多年以来,谷歌和其他公司的工程师训练机器人执行机械任务(例如翻转汉堡)的方式是使用特定的指令列表对其进行编程。然后机器人会一次又一次地练习该任务,工程师每次都会调整指令,直到得到满意的结果为止。 这种方法适用于某些有限的用途。但以这种方式训练机器人,既缓慢又费力。它需要从现实世界的测试中收集大量数据。如果你想教机器人做一些新的事情(例如从翻转汉堡改做翻转煎饼),你通常必须从头开始重新编程。 部分源于这些限制,硬件机器人的改进速度慢于基于软件的同类机器人。 近年来,谷歌的研究人员有了一个想法:如果机器人使用AI大型语言模型(来为自己学习新技能,而不是逐一为特定任务进行编程,会怎样? 据谷歌研究科学家卡罗尔·豪斯曼(Karol Hausman)介绍,他们大约两年前开始研究这些语言模型,意识到它们蕴藏着丰富的知识,所以开始将它们连接到机器人。 高容量视觉-语言模型(VLM)在web-scale数据集上进行训练,使这些系统非常擅长识别视觉或语言模式并跨不同语言进行操作。但要让机器人达到类似的能力水平,他们需要收集每个物体、环境、任务和情况的第一手机器人数据。 RT-2的工作建立在RT-1的基础上。这是一个经过多任务演示训练的模型,可学习机器人数据中看到的任务和对象的组合。更具体地说,谷歌的研究工作使用了在办公室厨房环境中用13个机器人在17 个月内收集的RT-1机器人演示数据。 谷歌首次尝试将语言模型和物理机器人结合起来是一个名为PaLM-SayCan的研究项目,该项目于去年公布,它引起了一些关注,但其用处有限。机器人缺乏解读图像的能力,而这是能够理解世界的一项重要技能。他们可以为不同的任务写出分步说明,但无法将这些步骤转化为行动。 谷歌的新机器人模型RT-2就能做到这一点。这个“视觉-语言-动作”模型不仅能够看到和分析周围的世界,还能告诉机器人如何移动。 它通过将机器人的动作转换为一系列数字(这一过程称为标注)并将这些标注合并到与语言模型相同的训练数据中来实现这一点。 最终,就像ChatGPT或Bard学会推测一首诗或一篇历史文章中接下来应该出现什么词一样,RT-2可以学会猜测机械臂应该如何移动来捡起球,或将空汽水罐扔进回收站垃圾桶。 02. 采用视觉语言模型进行机器人控制 RT-2表明视觉-语言模型(VLM)可以转化为强大的视觉-语言-动作(VLA)模型,通过将VLM预训练与机器人数据相结合,直接控制机器人。 RT-2以视觉-语言模型(VLM)为基础,将一个或多个图像作为输入,并生成一系列通常代表自然语言文本的标注。此类VLM已接受web-scale数据的训练,能够执行视觉问答、图像字幕或对象识别等任务。Google DeepMind团队采用PaLI-X和PaLM-E模型作为RT-2的支柱。 为了控制机器人,必须训练它输出动作。研究人员通过将操作表示为模型输出中的标注(类似于语言标注)来解决这一挑战,并将操作描述为可以由标准自然语言标注生成器处理的字符串,如下所示:
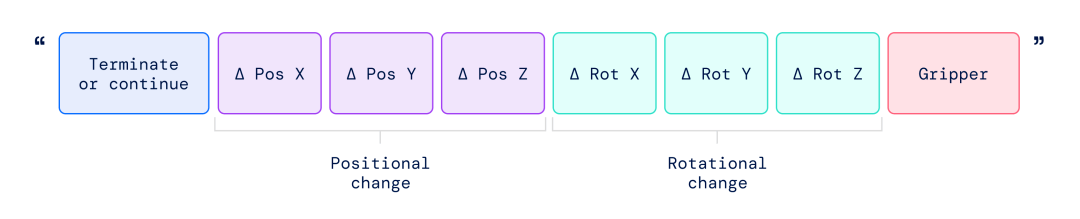
▲RT-2训练中使用的动作字符串的表示形式。这种字符串的示例可以是机器人动作标记编号的序列,例如“1 128 91 241 5 101 127 217”。 该字符串以一个标志开头,指示是继续还是终止当前情节,而不执行后续命令,然后是更改末端执行器的位置和旋转以及机器人夹具所需延伸的命令。 研究人员使用了与RT-1中相同的机器人动作离散版本,并表明将其转换为字符串表示使得可以在机器人数据上训练VLM模型,因为此类模型的输入和输出空间不需要改变了。
▲RT-2架构和训练:研究人员针对机器人和网络数据共同微调预先训练的VLM模型。生成的模型接收机器人摄像头图像并直接预测机器人要执行的动作。 |
 |手机版|小黑屋|博士驿站:连接全球智慧,共创博士人才生态圈
( 浙ICP备2023018861号-3 )平台提供新鲜、免费、开放、共享的科技前沿资讯、博士人才招聘信息和科技成果交流空间。
平台特别声明:线上内容(如有图片或视频亦包括在内)来自网络或会员发布,均已备注来源;本站资讯仅提供信息和存储服务。Notice: The content above (including the pictures and videos if any) is uploaded and posted by user , which is a social media platform and only provides information storage services.
|手机版|小黑屋|博士驿站:连接全球智慧,共创博士人才生态圈
( 浙ICP备2023018861号-3 )平台提供新鲜、免费、开放、共享的科技前沿资讯、博士人才招聘信息和科技成果交流空间。
平台特别声明:线上内容(如有图片或视频亦包括在内)来自网络或会员发布,均已备注来源;本站资讯仅提供信息和存储服务。Notice: The content above (including the pictures and videos if any) is uploaded and posted by user , which is a social media platform and only provides information storage services.
GMT+8, 2024-9-20 06:41
Powered by Discuz! X3.5
© 2001-2024 Discuz! Team.